Automatic Storage Management
ASM ist eine kleine spezielle Oracle-Instanz im Status "mount", die bei geringem Memory- und CPU-Verbrauch für die Vermittlung zwischen RDBMS-Instanz(en) und dem darunterliegenden Storage sorgt.
Auf ein und demselben Server kann eine einzige ASM-Instanz mehrere RDBMS-Instanzen mit Storage-Resourcen versorgen:
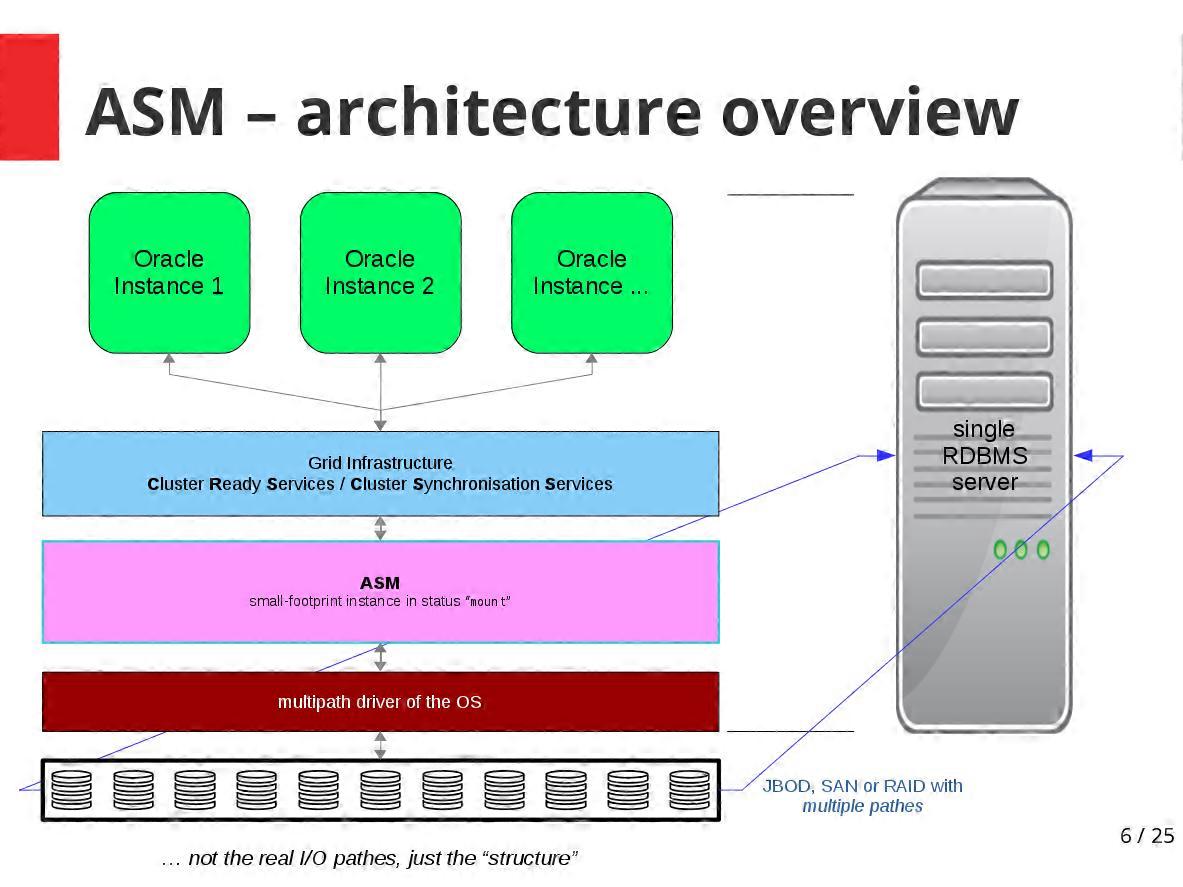
Prinzip:
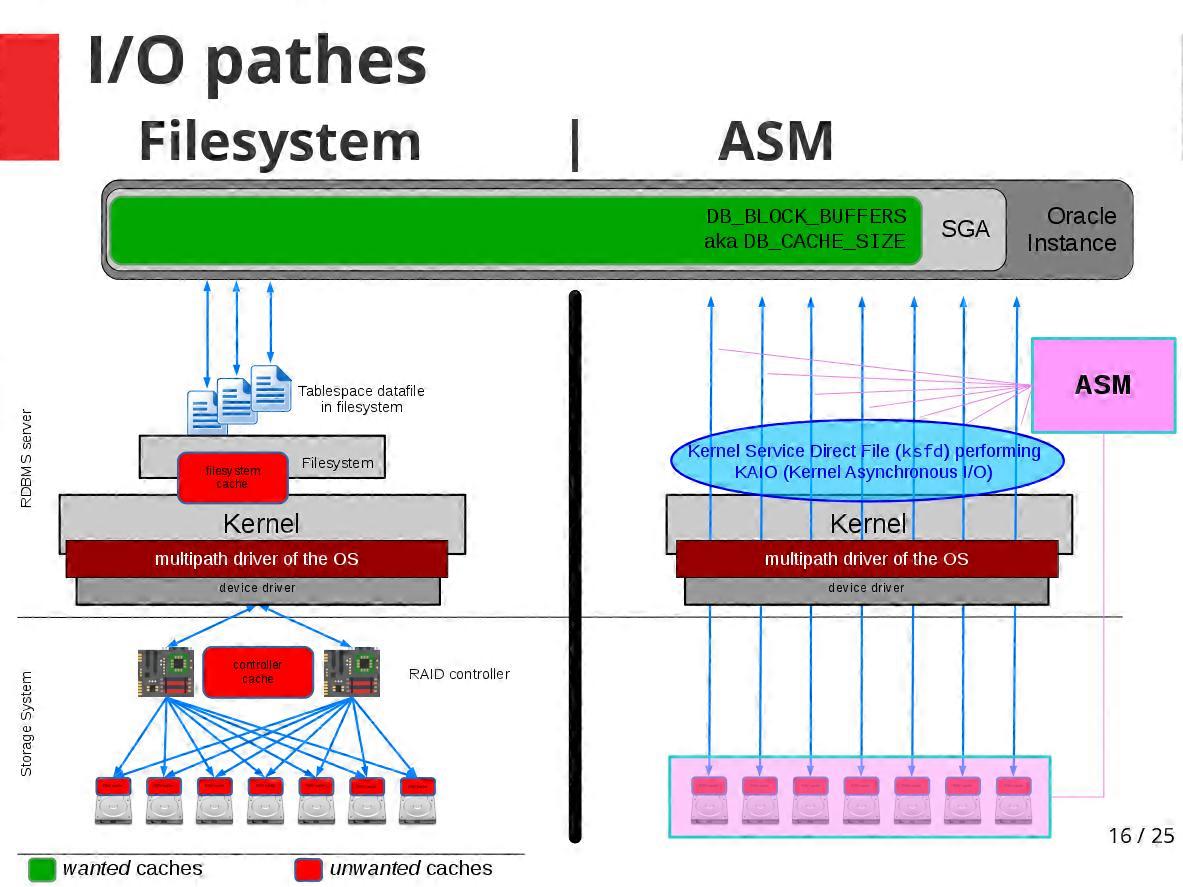
ASM öffnet die einzelnen Platten oder LUNs (eines SANs) direkt auf Betriebssystemebene. Es benötigt kein Filesystem (wie ext4 oder XFS oder NTFS), sondern gibt den Plattenplatz direkt an die RDBMS-Instanzen weiter.
Es vermeidet dadurch
- jeglichen Cache, der nicht applikationsbezogen ist (Filesystem-Cache, block cache im Kernel und ggf. den des RAID-Controllers)
- jegliches unnötige double-buffering (Umkopieren von user-space buffers in Kernel-buffer)
- jeglichen Overhead für Dateiverwaltung und den für das Logging heutiger journal-gesicherter Filesysteme (warum auch — das macht das RDBMS selbst sowieso besser)
Im Grunde ist der Plattenzugriff über ASM technisch gesehen mit dem früher üblichen Prinzip der "raw devices" vergleichbar. Dieser primitive Direktzugriff konnte damals zwar das Maximum an Performance aus den Platten herausholen, stellte den Administrator aber vor enorme Hürden bei Planung, Implementierung und Fehlersuche.
Tatsächlich greifen die RDBMS-Instanzen mit ASM direkt auf die Platten zu (also so schnell wie mit "raw devices") — ASM aber hütet den Disk-Zoo zuverlässig, verwaltet ihn für den DBA und sorgt intern für Redundanz und optimales Striping.
Dabei liegt ASM nicht im I/O-Pfad - stellt also nicht selbst einen Bottleneck dar, durch den alle Schreib- und Lesezugriffe hindurchmüßten:
Organisation:
⇒ Kapazität
ASM gruppiert Platten bzw. LUNs in diskgroups, die man entweder nach Art der Platten oder nach Kapazitätsüberlegungen anlegt.
Innerhalb einer diskgroup speichert ASM alle DB-Objekte nach dem "SAME"-Prinzip, dem für die Schreiblast von Datenbanken optimalen "Stripe All, Mirror Everything". Damit nutzt ASM für möglichst alle Objekte die Leistung aller Platten gemeinsam.
Dabei kann man pro Tablespace "coarse-grained" oder "fine-grained striping" festlegen, um z.B. Tabelleninhalte und Indices adäquat auf viele Platten zu verteilen. Übrigens ein Grund mehr, die Indices von den eigentlichen Daten zu trennen und in einen separaten TS mit "fine-grained striping" auszulagern.
⇒ Redundanz
Je nach Konfiguration spiegelt ASM durch Anlegen von mindestens zwei Kopien jedes wichtigen DB-Objekts.
Anders als RAID-Controller, die meist zwei bestimmte Platten aufeinander spiegeln, verteilt ASM die DB-Objekte aber auf alle Platten der diskgroup, so dass alle Kopien immer auf verschiedenen Platten liegen.
Um ASM dabei eine "Vorstellung" von denjenigen Komponenten des Storage-Systems zu vermitteln, deren Defekt zum Ausfall mehrerer Platten führen könnte, legt man innerhalb der diskgroups noch failgroups an. Beim Spiegeln berücksichtigt ASM dann, dass eine ganze failgroup (mit mehreren Platten) ausfallen könnte, und speichert die Kopien von DB-Objekten nie innerhalb derselben failgroup.
Desaster Recovery kostenlos
Stehen zwei (vergleichbar große) Storage-Systeme an verschiedenen Standorten ohne größere Latenzen zur Verfügung (z.B. per FibreChannel oder iSCSI über 9µm-Monomode-Fasern bis zu 10km voneinander entfernt), kann man ASM diese beiden Systeme als zwei failgroups definieren. Dann spiegelt ASM alle Datenbank-Inhalte an beide Standorte. Und das ganz ohne Zusatzkosten, die sonst für hersteller-eigene teure DR-Optionen anfallen würden, die außerdem oft noch voraussetzen, dass die beiden Storage-Systeme vom selben Hersteller stammen. ASM ist das egal — sobald das Betriebssystem die Platten "sehen" und ansteuern kann, spiegelt ASM darauf.
Selbstheilung im RAID
Definiert man in einem RAID-System keine hot spares (Platten, die nur auf den Ausfall einer ihrer Kollegen warten und im Normalbetrieb nichts zur I/O-Leistung beitragen), kann ein RAID-Controller beim Ausfall einer Platte nur eines tun: nichts. "Selbstheilung" im RAID kann nur auf hot spares stattfinden.
Selbst dann sind sind die verbliebenen Platten der LUN hoher Leselast und die eingesprungene hot spare einer sehr hohen Schreiblast ausgesetzt (meist bis zur Sättigung). Die Platten anderer LUNs im RAID sind nicht an der Selbstheilung beteiligt ("clustered RAID"). Wenn darüberliegende Datenbank-Instanzen von der betroffenen LUN lesen wollen, ist der I/O verlangsamt bzw. blockiert kurzzeitig.
Sollten an einem langen Wochenende mal mehr Platten ausfallen, als hot spares zur Verfügung stehen, bleiben die betroffenen LUNs im Zustand "degraded" und verkraften keinen weiteren Plattenausfall (außer bei RAID6).
Außerdem hat ein RAID-Controller keine Kenntnis davon, welche Plattenbereiche mit Daten belegt sind — für ihn sind es nur abstrakte Diskblöcke. Eine "hot spare" oder die ersetzte Platte muß er darum vollständig neu beschreiben: bei einer nur zu 50% mit Nutzerdaten gefüllten 2 TByte-Platte schreibt er die ganzen 2 TByte neu, obwohl die Hälfte davon leere Blöcke sind.
Migration mit herkömmlichem RAID
Bei einer Migration auf ein neues Storage-System geht es nicht unterbrechungsfrei: Datenbank herunterfahren, alle Daten sichern, das alte gegen das neue RAID-System austauschen, Daten wiederherstellen und die Datenbank wieder hochfahren.
Anders bei ASM.
ASM implementiert für Oracle-Datenbanken, was anderswo auch "de-clustered RAID" heißt — die Redundanz ist nicht mehr in einer LUN geclustert, innerhalb derer dann auch nur die Wiederherstellung stattfinden kann.
Stattdessen sind die Datenbank-Objekte auf viele Platten verteilt. Da im Normalfall immer mindestens zwei Kopien vorhanden sind, kann ASM bei einem Plattenausfall auch ohne hot spare sofort mit der Selbstheilung beginnen.
Dazu werden die verbliebenen Kopien aller durch den Ausfall "verwaisten" DB-Objekte gelesen und neue Kopien davon erzeugt. Da die "verwaisten" Inhalte auf viele Platten verteilt sind und ihre neuen Kopien wiederum auf viele (andere) Platten geschrieben werden, sind hier alle Platten an der Lese- und Schreiblast der Selbstheilung beteiligt.
Da ASM außerdem nicht einfach nur Diskblöcke, sondern nur die "verwaisten" DB-Objekte repliziert, wird nicht eine ausgefallene Platte im Ganzen, sondern nur der wirklich benötigte DB-Inhalt wieder redundant verfügbar gemacht.
Ist die betroffene diskgroup nur zu 50% gefüllt (was ~50% Füllstand all ihrer Platten bedeutet), muß ASM auch nur die Datenmenge neu schreiben, die der halben Größe der ausgefallenen Festplatte entspricht (im obigen Beispiel nur 1 TByte).
Diese beiden Mechanismen bewirken, dass die Redundanz schneller und effizienter wieder hergestellt ist — und das ganz ohne "hot spares", die im Normalbetrieb nichts zur I/O-Leistung oder Kapazität beitragen. Bei ASM bestehen die "hot spares" gleichsam aus dem gesamten freien Plattenplatz in der Diskgroup.
ASM verkraftet daher so lange weitere Plattenausfälle, wie freier Speicherplatz in der diskgroup vorhanden ist. (Ausnahme: ein zweiter Plattenausfall zerstört einige der verbliebenen (verwaisten) Kopien, bevor der erste Ausfall kompensiert werden konnte.)
Selbst wenn der freie Speicherplatz in der diskgroup erschöpft ist, könnten sich noch weitere Platten verabschieden — ASM kann deren Ausfall dann nur nicht mehr reparieren.
Migration bei ASM
Eine Migration auf ein neues Storage-System ist mit ASM unterbrechungsfrei möglich: das neue wird parallel (oder im daisy-chaining "hinter" das alte) an den DB-Server angeschlossen, die neuen Platten werden den bestehenden diskgroups hinzugefügt, die alten Platten per "drop disk" aus ASM entfernt und danach wird das alte System aus den Pfaden genommen.
Während dieses ganzen Vorgangs
- können die Client-Datenbanken oberhalb der ASM-Instanz weitgehend ungestört (wenn auch in ihrer I/O-Leistung beeinträchtigt) weiterlaufen
- bleiben Redundanz und Konsistenz der Datenbank-Inhalte immer erhalten
Was ASM nicht kann
ASM beherrscht kein RAID5(0) oder 6(0), sondern nur 2-way- oder 3-way-Mirroring. Das aber ist für gute Datenbank-Performance nur von Vorteil, denn alle paritätsbasierenden RAID-Verfahren liefern eher schlechte Schreibleistung für Datenbanken.
Aus Sicht des besonders kostenbewußten Storage-Käufers jedoch könnte Spiegelung "zu teuer" wirken — schließlich kann man damit ja vermeintlich nur die Hälfte des Plattenplatzes nutzen. Das gilt zwar für ein herkömmliches RAID im RAID1/10-Modus — nicht ganz so streng aber für ASM!
Richtig ist, dass ASM bei 2-way-Mirroring den Ausfall der Hälfte aller Platten nur dann vollständig kompensieren (also alle DB-Objekte erneut redundant verfügbar machen) kann, solange mindestens 50% des Platzes in der diskgroup frei sind. Wenn aber mehr als 50% des Plattenplatzes belegt sind (und man wieder den Extremfall mit 50% Plattenausfällen annimmt), kann ASM die Ausfälle zwar nicht zu 100% kompensieren, aber die eigentlichen Datenbank-Instanzen laufen so lange weiter, wie von jedem ihrer DB-Objekte mindestens noch eine Kopie vorhanden und lesbar ist.
ASM selbst versteht kein "multipathing". Für Platten bzw. LUNs, die über mehrere I/O-Pfade ansprechbar sind (z.B. FibreChannel oder SAS), muß deshalb das Multipathing des Betriebssystems eingerichtet werden (z.B. "dm-multipath" des Linux-Kernels).
ASM beherrscht (noch) keine Deduplikation oder Kompression der gespeicherten Daten. Für einfache Kompression der Tabelleninhalte läßt sich im RDBMS aber "table compression" benutzen. Wem das nicht reicht, der lizensiert von Oracle zur Enterprise Edition noch die ACO hinzu (Advanced Compression Option).
Anders als ein RAID-Controller kennt ASM den Einbauort einer Platte nicht (Rack - DiskTray - Slot). Ohne ein cleveres Namensschema für die ASM-Disks sind ausgefallene Platten nur schwer zu lokalisieren, wenn trotz des Fehlers ihre gelbe Error-LED mal nicht leuchtet. Das kann durchaus passieren, wenn der Plattenfehler nicht vom DiskTray, sondern nur von ASM festgestellt wird.
Fazit
- wer zur Redundanz die Spiegelung seiner RDBMS-Daten plant, kann sich mit ASM teure RAID-Controller sparen und die Platten in Form einfacher JBODs betreiben. Man kann darum mit ASM auch sehr gut ein älteres Storage-System wiederverwenden, dessen RAID-Controller nicht mehr unterstützt werden bzw. defekt oder zu langsam sind.
- die automatische Selbstheilung bei Plattenausfällen bezieht alle Platten ein und erfordert keine hot spares, die im Normalbetrieb nur "Däumchen drehen". Bei ASM ist quasi der gesamte freie Platz einer diskgroup "hot spare".
- im Normalbetrieb sind alle Platten gleichermaßen an der I/O-Performance beteiligt
- Kapazitätserhöhung durch mehr Platten führt direkt auch zu einer Erhöhung des I/O-Durchsatzes, denn mittels "rebalance" verteilt ASM auch die bestehenden Daten gleichmäßig auf alle (also auch die neuen) Platten, womit sich alle I/O-Vorgänge beschleunigen
Backlinks: 123ora:ORACLE RDBMS