Fileserver
Sowie mehr als eine Handvoll Linux-Maschinen mit Daten und Software zu versorgen sind, lohnt sich ein eigenständiger NFS-Fileserver.
Steht hinter dem Fileserver aber schnelles Storage und ist er an ein schnelles Netzwerk ≥10GBit/s angeschlossen und hat er viele NFS-Clients zu versorgen, stößt man mit einem herkömmlichen Fileserver schnell an Grenzen. Es kann soweit kommen, dass seine CPUs derart mit dem I/O zu den Platten und der Abarbeitung der NFS-/TCP-Protokolle ausgelastet sind, dass sich seine reine Rechenleistung als begrenzender Faktor herausstellt.
Man könnte nun den großen Schritt eines Paradigmen-Wechsels in Angriff nehmen — hin zu "distributed filesystems" (auch als "Cluster-Filesysteme" bekannt).
GPFS, Ceph, GlusterFS oder gar Lustre sind bekannte und im HPC-Umfeld etablierte Filesysteme, die das Problem "viele Daten möglichst schnell vielen Nodes bereitzustellen" gut lösen können. Sie verlangen aber z.T. enormen administrativen Aufwand beim Aufsetzen, dem täglichen Betrieb und ihrem Monitoring.
Bei diesen an sich exzellenten, vielfach als OpenSource verfügbaren Cluster-Filesystemen stehen außerdem oft Updates und Upgrades an, deren Installation nicht immer unterbrechungsfrei verläuft.
Neue Knoten in das Compute-Cluster zu integrieren, ist wegen der nötigen Treiber und Dienstprogramme administrativ aufwendiger und es kann dauern, bis sie in diese Strukturen vollständig eingebunden sind und effizient davon profitieren.
Und Cluster-Filesysteme wären bei einem diskless-Cluster, dessen ComputeNodes ganz ohne lokale Festplatten laufen, nicht einsetzbar.
Wenn also
- die Datenmengen groß,
- lokale Festplatten aber klein oder nicht vorhanden,
- das Administratoren-Budget (Geld und Zeit!) eng,
- zentrales Storage und Netzwerk aber schnell sind,
kann man statt auf Cluster-Filesysteme trotzdem auf schnelles NFS (v4) setzen und die bereits bestehenden Zugriffsstrukturen beibehalten. Insbesondere das Setup der versorgten Server und Workstations bleibt einfach – nur den NFS-Client aktivieren und ein paar Einträge in die /etc/fstab setzen oder AutoFS konfigurieren.
Doch mit einem "herkömmlichen" Fileserver auf Linux/x86_64-Basis und vielen Clients droht eben das obige Problem mangelnden Durchsatzes der Fileserver-CPUs, und die compute-intensiven Workloads bekämen ihre Daten nicht schnell genug.
Hilfe - mein Fileserver ist CPU-bound!
Dieses Problem läßt sich mit Fileservern lösen, die nicht auf herkömmlichen "General-Purpose"-CPUs basieren, sondern auf von vornherein parallel ausgelegten Architekturen.
Seriell...
Grundsätzlich sind die Kerne der bekannten "General-Purpose"-CPUs serialisierende Prozessoren. Trotz mehrstufiger Caches, Prefetching, Pipelining, mehrerer Queues und Threads pro Kern muss sich aller Code grundsätzlich doch im "Gänsemarsch" durch den Prozessorkern bewegen, der ihn ausführt: eine Instruktion nach der anderen:
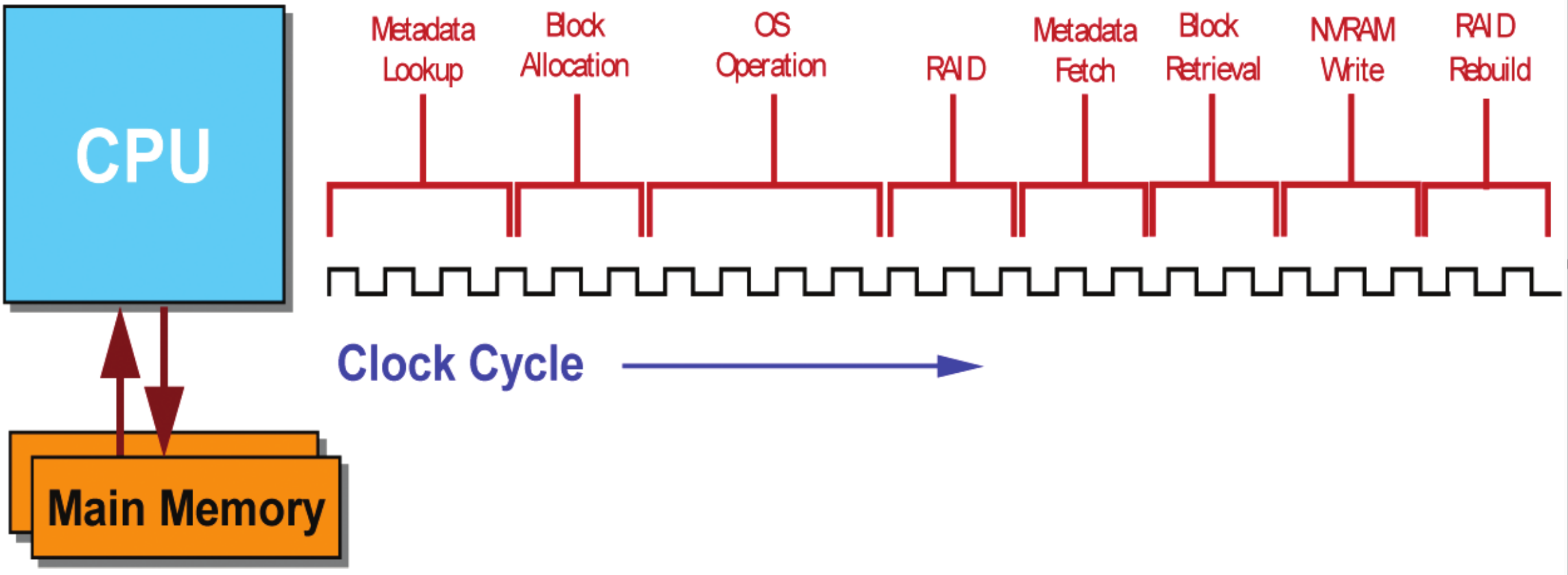
Vielkerner mit HyperThreading schaffen zwar, das Ganze in Grenzen zu parallelisieren — strenggenommen kann ein Achtkerner damit aber höchstens 16 NFS-Clients seine "volle" CPU-Aufmerksamkeit widmen.
Hinzu kommt, dass nicht nur das NFS-Protokoll (und das darunterliegende TCP bzw. UDP), sondern auch der gesamte Storage-Layer von den CPUs bewältigt werden will (Device-Treiber, MultiPathing, FibreChannel- bzw. SAS-Protokoll etc.).
... oder parallel
Im HPC-Umfeld sind FPGAs eine bewährte Technologie, um Algorithmen quasi "in Hardware zu gießen" und sie von diesen 'im Feld reprogrammierbaren Gate Arrays' wesentlich schneller auszuführen, als das eine starre "General-Purpose"-CPU könnte.
FPGAs kehren das Prinzip um, dass der Programmierer seinen Algorithmus auf eine bestimmte CPU hin optimieren muß - stattdessen entwirft man quasi den "idealen Prozessor" für einen bestimmten Algorithmus und gießt ihn in reprogrammierbare Hardware.
FPGAs können, hinreichend "breit" angelegt, sehr viele parallele Ausführungspfade gleichzeitig und unterbrechungsfrei abwickeln:
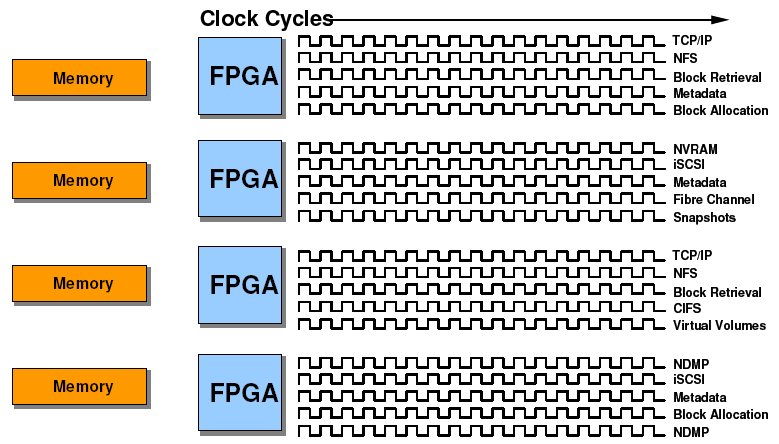
Was nutzt das in unserem Fall?
Am Markt sind Fileserver erhältlich, die sowohl das FibreChannel-Storageprotokoll zum Backend hin wie auch das NFS im Frontend zu den Clients hin in (mehreren) FPGA-Layern abbilden.
Hier gibt es keine Interrupts, kein Cache-Thrashing durch konkurrierende Threads oder gar mit vielen Extra-Clock-Zyklen bestrafte fehlgeschlagene Branch-Predictions.
Vereinfacht gesagt, steht jeder LUN im Backend-Storage und jedem NFS-Client im Frontend ein eigener, ununterbrechbarer Ausführungspfad durch die breit parallelen FPGA-Layer hindurch zur Verfügung.
Lassen Sie sich beraten, wenn Ihr(e) Standard-Fileserver der I/O-Last kaum mehr standhalten, Sie aber noch nicht gleich auf Ceph, GlusterFS oder Lustre umsteigen wollen — oder Sie ein rein diskless Cluster betreiben (wollen), für das diese Filesysteme sowieso nicht in Frage kämen.
Backlinks: 123ora:Linux:Software-Management