Beschleuniger
Im High-Performance Computing unterscheidet man "normale" Prozessoren ("general purpose CPUs") von "Beschleunigern". Bislang werden folgende Technologien als Beschleuniger eingesetzt:
FPGAs
Field-Programmable Gate Arrays sind "im Felde", also beim und vom Kunden, umprogrammmierbare ASICs. Sie bestehen aus vielen, anfangs unkonfigurierten Logikgattern (Gate Arrays), in die man einen bestimmten Bitstring belädt. Dieser Bitstring verkörpert einen ComputeKernel, der die Logikgatter quasi in den "optimalen Prozessor" für einen bestimmten Algorithmus verwandelt. Den Bitstring erstellt man mit speziellen Compilern, die VHDL- bzw. Verilog-Code oder auch Hochsprachen-Konstrukte in FPGA-Bitstrings übersetzen.
Der Programmierer programmiert hier nicht ein Programm im eigentlichen Sinne, sondern eine "Datenfluss-orientierte" Beschreibung dessen, was der Wunschprozessor mit den Input-Daten machen soll.
Neben den Logikblöcken verfügen FPGAs über möglichst viele I/O-Pfade "nach außen" sowie über Zwischenspeicher für I/O und Daten:
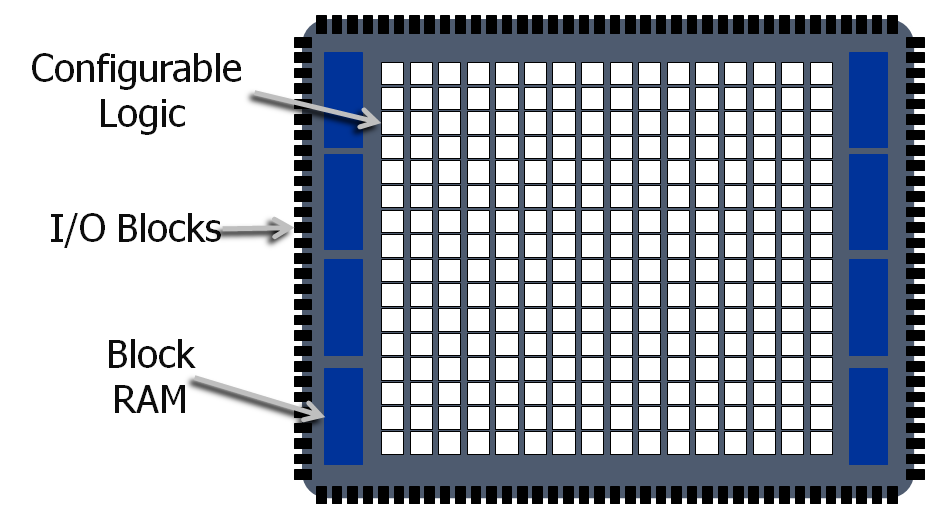
FPGAs haben gerade im wissenschaftliches Rechnen an Bedeutung verloren, da sie zum einen nicht in jedem Rechner vorhanden und zum anderen ihre Beschaffung wie auch die Code-Entwicklung für sie z.T. teuer sind. In der Kryptologie hingegen sind sie noch weit verbreitet, weil sie gängige (und in der Entwicklung befindliche) Verschlüsselungsverfahren sehr schnell simulieren und ausführen können.
Bislang noch unschlagbar sind die FPGAs im Hinblick auf ihre Energieeffizienz: in "GFLOPS pro Watt" gemessen, sind sie die ökonomischsten Beschleuniger — weit sparsamer als CPU und GPU.
Spezialprozessoren
... wie INTeLs Phi ("Knights Landing"). Diese sind nicht "im Felde" umprogrammierbar, bieten aber eine auf Hochdurchsatz-Rechnen hin optimierte, "vielkernige" Architektur. Sie teilen sich mit den FPGAs den Nachteil, nicht in jedem Computer zu stecken und teuer in Beschaffung und Code-Entwicklung zu sein. Auch sie führen nur exklusiv für ihre Architektur übersetzte Spezialprogramme aus.
2017-11-15: Intel kündigt das Auslaufen der "Xeon Phi"-Reihe an ("Knights Hill" und "Knights Mill" werden nicht mehr erscheinen).
GP-GPU
General Purpose computing on Graphics Processing Units — das ist Hochgeschwindigkeits-Rechnen auf Grafikkarten.
Seit dem Beginn der 3D-Ära auf dem Standard-(Gamer-) PC haben Performance und Durchsatz normaler Grafikkarten enorm zugelegt, befeuert durch immer aufwendigere Spielewelten. Insbesondere das Berechnen der jeweiligen ViewPorts (nach jeder Drehung/Bewegung von Spielfiguren) findet nach dem SIMD-Prinzip statt — Single Instruction, Multiple Data. Ein und dieselbe geometrische Transformation muss auf viele Bildpunkte/Texturen angewendet werden.
Daher sind Grafikkarten darauf spezialisiert, wenige (z.T. aber auch komplexe) Transformationen auf viele Daten möglichst schnell anzuwenden.
Gegenüber FPGAs und Spezialprozessoren haben GPUs zudem den Vorteil, in beinahe jedem Computer zu stecken — damit ist die Wahrscheinlichkeit hoch, dass sie von vielen Entwicklern (und vielen Studenten interessanter Fachrichtungen...) als ihr favorisierter Beschleuniger genutzt werden.
Auch das GP-GPU-Computing verlangt sogenannte Compute-Kernel, die der Programmierer in Hochsprachen erstellen, mit einem Compiler übersetzen und in die Grafikkarte laden muss. Dabei helfen aber die zwei Standards OpenCL und CUDA, die mit Bibliotheken die Erstellung solcher Kernel vereinfachen.
OpenCL
Die "Open Compute Language" ist ein massgeblich von Apple initiierter Standard, der unter Mitarbeit von AMD (ehemals ATI), IBM und NVidia entstand. Heute betreut ihn die "Khronos-Group" als offenen Standard, d.h. ohne Lizenzgebühren nutzbar und im Source Code verfügbar.
Er dient der Entwicklung gemischter Anwendungen — in OpenCL kann man die normalen CPUs und die GPUs aus demselben Code heraus ansteuern.
CUDA
Die "Compute Unified Device Architecture" ist ein proprietärer Standard von NVidia, der nur für deren GPUs verfügbar ist. Da NVidia aber sowohl bei Consumer-Grafikkarten als auch bei HPC-Beschleunigern Marktführer ist, haben sich CUDA-basierende Anwendungen im wissenschaftlichen Rechnen weit verbreitet.
Auch in CUDA läßt sich gemischter Code erstellen, der sowohl normale CPUs als auch GPUs nutzt.
Generell gilt, daß NVidia auf seinen Karten "sein" CUDA vollumfänglich unterstützt und OpenCL eher etwas "stiefmütterlich" behandelt. AMDs "FirePro"- und "Radeon"-Karten hingegen bieten bessere OpenCL-Unterstützung, aber kein CUDA.
Wenn Sie eine CUDA- oder OpenCL-fähige, rechenintensive Anwendung haben, stehen Ihnen grundsätzlich zwei Vorgehensweisen zur Verfügung:
"echte" Beschleuniger-GPUs
... wie zum Beispiel NVidias "Tesla"/"Volta"/"Ampere"-Serie zum Einbau in Compute-Cluster oder große Server (ganz ohne Monitor-Ausgänge), oder auch deren "Quadro"-Serie für Workstations (steuern gleichzeitig noch Monitore an).
Hier findet man die üblichen "Profi"-Features: Quadro (ab der "Fermi"-Chipgeneration) und Tesla et al. haben z.B. den Vorteil von ECC-gesichertem Grafik-RAM, das kippende Bits (und damit falsche Ergebnisse) korrigieren bzw. zumindest entdecken kann. Sie bieten natürlich volle Unterstützung für CUDA, z.B. die für wissenschaftliche Berechnungen wichtige DoublePrecision-FloatingPoint-64-Genauigkeit (binary64-Zahlenformat) in optimaler Geschwindigkeit.
Consumer-GPUs
Seit einiger Zeit untersagt NVidia in den Lizenzbedingungen ihres Treibers den Einsatz von Consumer-Grafikkarten in Rechenzentren oder Compute-Clustern - daher ist der u.a. Einsatz nicht von den Lizenzbedingungen des NVidia-Treibers abgedeckt.
Consumer-GPUs sind auf ihren ursprünglichen Zweck hin — schnelle Bildberechnung und -Ausgabe — optimiert, wofür vor allem SinglePrecision-FloatingPoint-32 (SP-FP32) benötigt wird. Ihnen fehlt die den Profi-Serien vorbehaltenen Funktionen ECC-GRAM und die Optimierung auf die wissenschaftliche Zahlendarstellung. Mit gewöhnlichen Consumer-GPUs würde die DP-FP64-Leistung ca. nur 1/32 ihrer SP-FP32-Leistung betragen!
Sichert Ihnen Ihr Software-Hersteller also zu, dass seine Anwendung keine DP-FP64-Arithmetik einsetzt (und auch in absehbarer Zukunft nicht darauf wechseln wird), sondern mit SinglePrecision-FP-32 oder gar Integer-Arithmetik auskommt und Sie auf ECC-GRAM verzichten können, spricht nichts gegen den Einsatz der viel preiswerteren Endkunden-Grafikkarten. (Beispielsweise hat das Memorial Sloan Kettering Cancer Center sehr gute Erfahrungen mit seinem "Lilac"-ComputeCluster mit Consumer-Grafikkarten gemacht.)
Lassen Sie sich beraten!
Links:
Backlinks: 123ora:Fileserver